最近機械学習の勉強をしているのですが、モデルのアルゴリズムをなんとなく理解してモデルの使い方をなんとなく理解しても、実際にどう活用すればよいか良いアイデアが浮かばずにいました。そんな時に以前ちらっと見つけたKaggleというプラットフォームを思い出し、そこにあるコンペティションをやってみたら結構楽しく進めることができました。
kaggleとは
kaggleはサンフランシスコのスタートアップが運営するサイトというかプラットフォームで、企業がひとかたまりのデータとそのデータを元にしたお題を提供し、一般の個人やチームがお題に対して最適なモデルを構築して、その出来を競い合うといったものです。
それぞれのお題には期限と賞金が設定されており、今だとたとえばTHE HOME DEPOT社(住宅リフォーム・建設資材・サービスの小売チェーン)が、サイト上での商品検索クエリと検索結果の関連性を図るモデル作成のお題を、4万ドル(450万円)の賞金付きで出したりしています。
日本で言うとホームセンター系の小売ですが、商材が多岐にわたるため、入力された検索クエリに合致した検索結果を出すことがとても大事なんだと思います。
企業は賞金を出す代わりに作成されたモデルに関する権利を取得し、実際のビジネスに活かせる。
参加者は活発なコミュニティで統計・機械学習・人工知能の技術を競い合いながら勉強することができ、さらにjob oportunityも得られる。
といったビジネスモデルのようです。おお、カリフォルニアのスタートアップって感じ!
チュートリアルはタイタニック号の生存予測
お題のイメージとか提出までの流れを知るために、用意されているチュートリアルを見てみました。
チュートリアルのお題はタイタニック号の生存予測です。タイタニック号に乗っていた乗客の名前・性別・チケットの値段・年齢などがトレーニングデータとテストデータに分けられ、トレーニングデータを基にモデルを作成し、テストデータの解答を予測。予測結果を答えとして提出し、提出しているユーザーの中での順位が出ます。
僕はPythonとscikit-learnを使って機械学習の勉強をしているので、Python用のチュートリアルを見ました。
Python用のチュートリアルは3つにわかれています。
ここでは機械学習ライブラリなどは使わずに、『性別で生存予測をする』『性別とクラスとチケットの値段で生存予測をする』の2パターンをそれぞれ場合分けのロジックを実装しているものです。
Getting Started With Python II
このチュートリアルではPandasライブラリの基本的な活用方法が説明されています。
Nunpyやcsvライブラリだと全ての値を同一のデータ型で保持しないといけないが、Pandasなら列毎に異なるデータ型で保持できるからよりExcelみたいに直感的に使えるよ!といったことが書かれていました。この部分はPandasの説明が日本語で書かれている記事なんかで理解する方が良いと思います。
Getting Started With Random Forests
ここではscikit-learnのRandom Forestを用いて生存予測モデルを構築します。
乗客のデータは名前とかクラスとかが文字列で書かれていたり、欠損しているデータも多く、そんなトレーニングデータだとscikit-learnは受け付けない。でも2つめのチュートリアルで教えたPandasを使えばうまいこと整形できるよ!成形できたらモデルを使って予想をするのは簡単だよ!
といった内容が書かれていました。
トレーニングデータやテストデータ、各チュートリアルで作られたモデルや結果はDataに全て載っています。実際にどうやってモデルを作っているかはここを見ればわかります。
サンフランシスコの犯罪予測問題をやってみた
サンフランシスコの過去の犯罪データを基に、犯罪の種類を予測するモデルを作る、というお題があったのでやってみました。ちなみにこのお題はplaygroundに分類されており、まあ試しにやってごらんよ、くらいの問題です。
お題の概要
サンフランシスコは近年所得格差や住宅不足が社会問題となっているらしく、犯罪発生率も低くないとのこと。このお題では過去12年分の犯罪のデータを基に、犯罪の種類を予測するモデルを作ります。与えられるデータは、例のごとくトレーニングデータとテストデータです。両方のデータには『発生年月日』『曜日』『どの警察署の管轄か』『住所』『緯度』『軽度』が与えられ、トレーニングデータには追加で『犯罪のカテゴリー』『犯罪の詳細』『事件結果』(捕まえたとか逃げられたとか)といった情報が与えられ、これらを基にテストデータの『犯罪のカテゴリー』を予測します。
予測結果をcsvで提出すると、順位がその場で分かります。
作ったモデル
kaggleでは自分の作ったモデルを公開することができるので、既に公開されているモデルを参考に作ってみました。
モデルとしては超単純で、『曜日』『どの警察署の管轄か』を基にDecisionTreeで分類するものです。
DecisionTreeを採用した理由は、最近勉強したので使ってみたかったからです。
# coding: UTF-8
import pandas as pd
import numpy as np
import gzip,csv
from sklearn.tree import DecisionTreeClassifier
################################################
# train.csvをpandasで読み込み、今回は使わない列を削除
# yは['WARRANTS' 'OTHER OFFENSES' 'OTHER OFFENSES' ..., 'LARCENY/THEFT''VANDALISM' 'FORGERY/COUNTERFEITING']
train = pd.read_csv(r'train.csv')
y= train.Category.values
train = train.drop(['Address','Category','Dates','Descript','X','Y','Resolution'],axis=1)
################################################
# scikit-learnのDecisionTreeは文字列不可なのでInt型に置き換え
# 置き換え情報はdictに格納
# dict = {'DayOfWeek': {'Monday': 1, 'Tuesday': 5, 'Friday': 0, 'Wednesday': 6, 'Thursday': 4, 'Sunday': 3, 'Saturday': 2}, 'PdDistrict': {'CENTRAL': 1, 'NORTHERN': 4, 'INGLESIDE': 2, 'PARK': 5, 'MISSION': 3, 'TENDERLOIN': 9, 'RICHMOND': 6, 'TARAVAL': 8, 'BAYVIEW': 0, 'SOUTHERN': 7}}
days = {}
cnt=0
for i in np.unique(train.DayOfWeek.values):
days[i] = cnt
cnt+=1
dict ={'DayOfWeek' : days}
PdDis = {}
cnt=0
for i in np.unique(train.PdDistrict.values):
PdDis[i] = cnt
cnt+=1
dict['PdDistrict'] = PdDis
train = train.replace(dict)
################################################
# DecisionTreeのモデルを生成し、train(トレーニングデータ)で学習
model = DecisionTreeClassifier(random_state=0)
model.fit(train,y)
################################################
# test.csvを読み込み、使わない列を削除して学習済みモデルに当てはめる 学習結果はpredicted
test = pd.read_csv(r'test.csv')
idx = test.Id.values
test = test.drop(['Id','Dates','Address','X','Y'],axis=1)
test = test.replace(dict)
# predict_probaは予想される確率を返す関数
# 同じ行(テストデータ一件あたり)の列(予想される確率)を全て足すと1になる
predicted = np.array(model.predict_proba(test))
################################################
# kaggleに提出するためのcsvファイルをzip形式で作成
labels = ['Id']
for i in model.classes_:
labels.append(i)
with gzip.open('SFCrimeOutput.csv.gz', 'wt') as outf:
fo = csv.writer(outf, lineterminator='\n')
fo.writerow(labels)
for i, pred in enumerate(predicted):
fo.writerow([i] + list(pred))
結果
さて、この作ったモデルで結果を作成し、kaggleにアップします。
アップに5分、結果取得に1分くらいかかりました。
結果はこちらです。
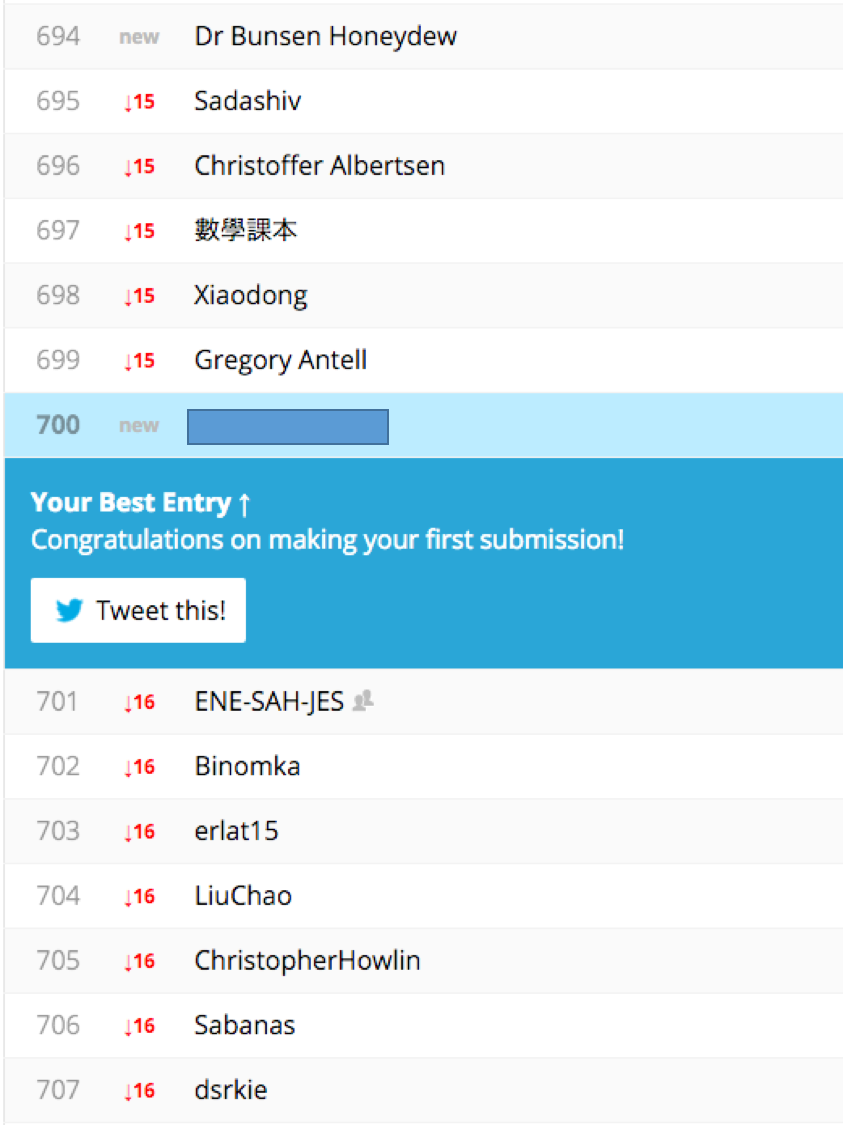
ピッタリ700位でした!
このお題に参加している人は1200人くらいなので、低いです。
順位を上げるための考察
今回はモデルを構築するための軸が全然少なかったので、この辺りはもっと活用する必要がありそうです。
また、地域を区切って分析するとおもしろいよ、とkaggleの説明にヒントとして書いてあったので、緯度と経度から地域を区切って、地域毎に分析すると効果的ぽいです。
また、今回は何も考えずにDecisionTreeを採用しましたが、お題の傾向に合わせてモデルを選択することが、当たり前ですが必要です。
この辺りは機械学習のキモの部分らしいので、色んなモデルを勉強して、kaggleとかを使って実際にそのモデルを試すということを繰り返していきたいです。